Classification method
Remodel the problem
In this part, we divided ROI into three groups: [0,3], (3,5], and (5,+∞), corresponding to bad, good, and hit movies. The reason of doing so is that, the 'budget' of a movie usually refers to its production cost, but revenue will go to not only the production companies, but also movie theatres, publicity department and pulishers, etc. So in practice, a movie is considered to begin to earn profit if its ROI reaches 3. So the prediction task truns to a classification problem.
Classification methods
We tried several machine learning methods on the datasets we collected using sklearn classifiers: k-nearest neighbor (KNN), decision tree classifier (CART), linear support vector machine (LinearSVC), two random classifiers: random forest (RF) and extra tree (ExtraTree), and two boosting methods: AdaBoost and gradient boosting (GB). These classifiers are run on our movie dataset. We used 10-fold cross validation for estimating general performance of methods.
We use F1-score to evaluate performance of our methods. The results are shown in the following table. We also generated a confusion matrix for CART, which reaches the highest macro F1-score among all tests.
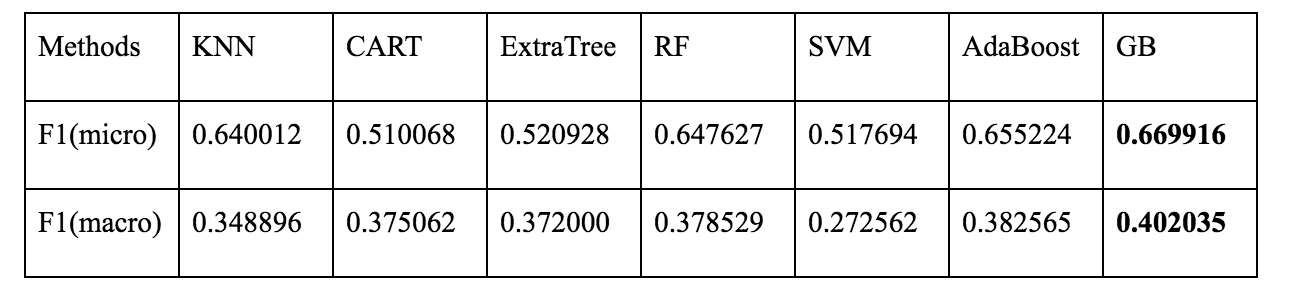
Table: F1-scores on different methods
From the table we can see boosting methods outperform other classifiers. But after we took a closer look on the details of their F1-scores, we found that CART gave better F1-scores on all three classes, while GB and AdaBoost gave such high F1-score on one class (bad movies, i.e. the largest class) that even macro F1-scores were pulled up by that single score. So CART actually performs better.

Confusion matrix of CART model prediction results
The figure of confusion matrix also shows that there is a tendency that our classifier would like to underestimate the performance of a movie (see the darker cells on lower-left corner). Our guess is that, aside from the unbalanced training set, movies that turned out to have bad box office performance might have more common characteristics than those whose performance were good. Also, from investor’s point of view, underestimating a movie would not lead to greater loss of profit than overestimating one, so the tendency toward lower-left corner would actually be better for investors than a upper-right tendency in practice.
Importance of features
Among the methods we talked above, we choose Lasso regression and CART to interpret contributions or levels of importance of different features in prediction procedures. We used our whole dataset to train the regressor and classifier.
In the Lasso regressor, ‘budget’, ‘crew’ and ‘youtubeView’ (in this order) contribute the most, while ‘runtime’ and ‘cast’ contribute very less.
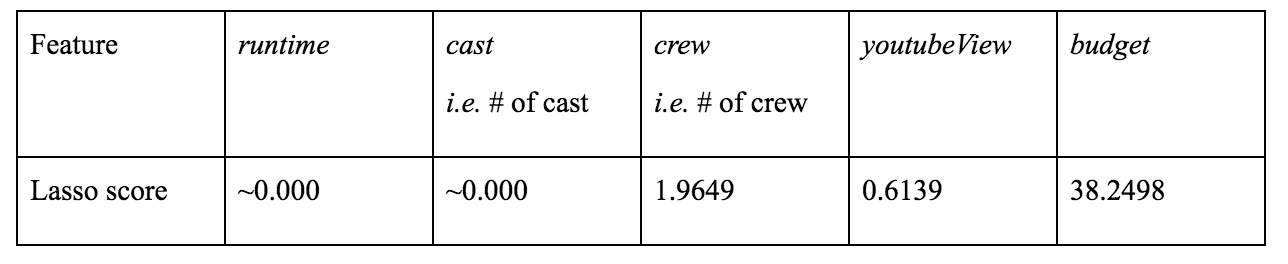
Table: Lasso scores on features
In the decision tree classifier (CART), we see that the root node is ‘youtubeView<=7408751.5’, and two nodes on the second level are ‘budget<=15200000’ (for True on root node) and ‘cast<=42.5’ (for False), Which indicates that these three features contribute the most when the CART model classifies new entries.